Ina Sîtnic
Department of Translation, Interpretation and Applied Linguistics
Moldova State University
inasitnic@gmail.com
Abstract
This article aims at assessing second year undergraduate students’ memory, attention and concentration skills in classes of consecutive interpreting (CI) by means of applying a Distributed attention exercise. The study was conducted at the Department of Translation, Interpretation and Applied Linguistics, Moldova State University. It focuses on determining the number and types of errors that students make during CI from English into Romanian, the possible causes of such errors and relevant exercises to train memory, attention and concentration competences. It looks at two samples of students that represent the experimental group (EG) and the control group (CG). The main hypothesis we put forward in this paper is whether and to what extent the translation exercise applied to the EG prior to discourse interpreting improves the quality of the CI product compared to the group of students who do not have any CI exercise before interpreting the same discourse.
Aim, objectives and hypothesis of the study
This paper aims at determining the quality of the interpretation versions provided by BA students from the Department of Translation, Interpretation and Applied Linguistics (Department TIAL), Moldova State University. The participants in the study are second year BA students whose mother tongue is Romanian and who study English as a first foreign language. The study was carried out in the first semester of students’ classes of Consecutive interpreting (CI).
The objectives of the paper are:
- To identify and analyse the types of errors that students make;
- To determine the causes of errors;
- To establish the prevalence of CI categories and number of errors in the EG and the CG;
- To determine whether the strategy of applying the memory, attention and concentration exercise prior to CI of the discourse will improve the quality of interpretation in the EG in terms of number and types of errors.
The main hypothesis to be tested in this paper is formulated as follows: Students in the EG will prove better performance results when applying the memory, attention and concentration exercise prior to the discourse interpretation compared to the students in the CG who do not have the exercise prior to discourse interpreting. This assumption originates in personal didactic observations during classes of consecutive interpreting. We intend to uphold or reject the stated hypothesis by comparing error rates in the EG and CG.
General notions on competence of consecutive interpreting and error analysis
In this study the notion of interpreting competence has a central role because it represents the object of study of this research. But due to the diversity of ideas and approaches to the notion of interpreting competence it is difficult to state one definition and determine a common thinking of the skills that make it up. At the same time there is a wide variety of interpretations that cover the notion in question and many more studies carried out equally by scholars and practitioners in the field of interpreting competence and interpreter training (D. Gile, S. Kalina, G. Lungu Badea, J. Z. Forte, M. Cecot, W. Zhe), types of abilities that one should possess in order to perform his/her activity at a high level standard (D. Gile, S. Kalina, W. Keiser, A. Riccardi), interpretation quality assessment (H. Vermeiren), error analysis (M. S. Alessandrini W. Hairuo), curriculum design, consecutive interpreting and consecutive skills (P. Sveda) etc.
In order to prove the broad interlinguistic spectrum of denominations for the notion under study we outlined a timeline analysis of the terminology used for the notion of interpreting competence used in the scientific literature which is presented in Table 1.
Table 1. Terminological variations of the notion of interpreting competence
| Authors | Denominations proposed for the notion of interpreting competence in the published literature |
| D. Gile (1995, 2009) | Fr. compétences en interprétation |
| W. Keiser (1997) | Fr. aptitudes à l’interprétation |
| F. Pöchhacker (2004) | En. competence in interpreting |
| M. Russo, P. Salvador (2004) | En. aptitude to interpreting |
| И. С. Алексеева (2004) А.П. Чужакин, С.Г. Спирина (2007) | Ru. навыки устного перевода |
| C. Petrescu (2005) G. Lungu Badea (2012) | Ro. competența interpretativă |
| H. Vermeer, J. Van Gucht, L. De Bontridder (2009) | En. translation ability (with reference to interpreting) |
| A. Бутусова (2012) | Ru. компетенция устного переводчика |
| A.Gillies (2013) | En. interpreting skill |
| S. Kalina (2016)
R. Setton, A. Dawrant (2016) |
En. interpreting competence |
| B. Ahrens, E. Tiselius, A. Hild (2017) | En. Interpreting competence(s) |
Memory and concentration play a crucial role in the process of CI. In this respect, academics and practitioners suggest working hard on the level of attention and concentration from the very beginning of the development of one’s interpreting competences.
When mentioning the qualifications an interpreter needs with regard to memory and concentration M. Phelan states: “Interpreting is a demanding job […]. The interpreter needs a good short-term memory to retain what s/he has just heard and a good long-term memory to put the information into context. Ability to concentrate is a factor as is the ability to analyze and process what is heard” (Phelan 2001, 4-5). The aim of memory training in interpreting is to achieve a better understanding of the source-language (SL), which will ultimately lead to adequate interpreting.
Among the problems some novice students report during classes of CI is the underdeveloped memory and the lack or loss of concentration to perform the interpreting task. The first step in CI is to understand the message in the SL, then memory training exercises will be provided early in the process of interpreter training.
Here are some memory-training exercises we suggest for better performance in classes of CI:
- retelling in the SL – reproducing the information on a particular subject;
- shadowing with a twist – repeating the speaker’s words in the same language. The repetition is done after a short pause following the speaker’s utterance, which makes the shadowing more like CI;
- categorization – grouping items with the same properties;
- comparison – determining the similarities and differences between facts, things, events;
- generalization – drawing general conclusions from particular examples or message from the provided text;
- description – depicting a situation, a person, an object, an experience;
- mnemonics for memory exercises – using different types of mnemonics like name mnemonic (creating names of persons or things from the first letter of each word in a list of items that need to be memorized), expression or word mnemonic (forming phrases or words from the first letter of each item in a list), rhyme mnemonics (inserting information to be remembered in the form of a poem), note organization mnemonics (outlining main ideas from details, reorganizing a written text into schemes that contain symbols, abbreviations, signs, etc.), image mnemonics (reorganizing information in the form of mental or graphical images), spelling mnemonics (remembering commonly confused words if attributing them easier to remember words) to promote information recall;
- exercises with background noise interferences to prevent information loss and boost concentration as well.
Attention and concentration are as essential as memory skills for CI as their loss during an interpreting assignment may lead to disastrous consequences and incapacity to regain control over the process of interpretation. Some of the causes leading to the loss of attention and concentration are vulnerability to rapid circumstantial changes (unknown words or phrases, numerals, enumerations, etc.) and slow reaction to quick situational changes. When in stressful circumstances during CI students have to put much psycho-cognitive effort into tasks of CI. They have to:
- Listen to, analyze the information and take notes;
- Reproduce the information by deciphering the notes and resorting to short-term memory for further details related to the discourse while (possibly) hearing some background noise.
Consequently, the ability to cultivate distributed attention between the phases of SL comprehension and target-language (TL) production is a prequisite for successful performance in interpreting.
Of course, concentration cannot be constantly retained but it can be trained to last longer. In order to train concentration (re)gain period to last shorter we may suggest the following exercises:
- Repetition of words, numerals and phrases at different speed. Most of the words are logically connected but some of them are irrelevant. Students’ attention is used to the logic and every time they hear an irrelevant word their brain will react with a concentration loss;
- Change in the speaker’s utterance – students listen to 5-6 logically linked words or phrases and then they must quickly repeat them to catch up with the speaker while s/he continues reading the sequence of words in order to distract students. This exercise aims to adapt student-interpreters to unexpected changes in speaker’s utterance speed.
- Eliminating the effect from background noises – the students have to count down in a normal voice from 100 to 0, thus making some noise in the classroom and preventing their colleagues from clearly perceiving the information. This stressful situation helps the students go through concentration shift quicker and have a longer concentration regain period.
Student-interpreters should know that there can never be ideal conditions for interpreting. The more obstacles there are the more mental effort is needed to put in order to do well in CI. Nevertheless, for better results it is important that the above mentioned exercises be performed regularly during classes and it is also essential that students be encouraged to practice them after classes.
The assessment of the quality of students’ product of CI by means of determining the number and types of mistakes and errors is a long time debated subject in the context of interpreter training in the academic environment. In the field of applied linguistics there are different opinions with reference to the notions of mistake and error. Linguists like H. C. Barik, D. Gile, D. Gouadec, Ch. Nord, Ch. Waddington, G. Lungu-Badea and others use the notion of error. It is intensely manipulated in the field of translation and interpreting studies and is perceive as a disagreement or a distortion in the process of transferring the original discourse into its translated version, having an impact that irremediably modifies the quality of the product of interpreting. Other scholars, though, attribute these notions to particular contexts. Thus, R. Gefen defines the mistake as a gap at functional level. It is occasional and is most often caused by extra-linguistic factors like tiredness, haste or background noises when listening to the discourse while the error originates in semantic, lexical, grammatical, etc. discrepancies between the original discourse and its translated version.
With regard to the translation mistake G. Lungu-Badea states that it is not only a fissure, i.e. a deviation to the chosen interpreting approach, as stated by Ch. Nord (Nord 2005, 186) but “It is an error in the target-discourse (TD) that emerges as a result of wrong interpretation or erroneous comprehension of the unit of interpretation in the original discourse” (Lungu-Badea 2012, 79). In Lungu-Badea’s opinion this type of error is manifested through false meaning, nonsense, addition, omission, ambiguity, false analogy, etc. The author identifies the notion of interpreting mistake with error of interpreting.
According to D. Gile’s Effort Model problem triggers are “associated with increased processing capacity requirements which may exceed available capacity or cause attention management problems or with vulnerability to a momentary lapse of attention of speech segments with certain features” (Gile 2009: 171).
Researchers in the field propose classifications of errors of interpretation according to certain criteria. The Canadian interpreter H.C. Barik was the first to point out the discrepancies of content between the SD and the TD. He defined these discrepancies and suggested, in this respect, a classification that includes omissions, additions, and substitutions.
According to the sources and causes of errors D. Gile groups them into errors of meaning, language errors, errors of terminology and specialized phraseology while D. Gerver categorises them in omissions, substitutions and corrections. In „Mic dicționar de termeni utilizați în teoria, practica si didactica traducerii” G. Lungu-Badea divides errors of interpretation into two broad categories: minor errors (stylistic inconsistencies) that do not cause the alteration of the message and major errors (nonsense and misinterpretation) that presuppose deviations from the intention of the original discourse. The author signals out the following errors: syntactic, lexical and semantic errors caused by approximate or inadequate solutions to problems or difficulties of interpretation; errors determined by a wrong comprehension or an uninspired expression in the TL; individual errors triggered by difficulties or collective errors triggered by problems of interpreting.
Building on the existent categories of errors in the scientific literature and taking into account the types of interpreting skills that we intend to address in this paper, having regard to the short-CI mode employed for this study as well as to the linguistic combination under study (English-Romanian) we shall approach the following typology of errors: intralinguistic errors of expression which includes pronunciation, morphological and syntactical mistakes. The causes that foster their occurrence are the low level of education of the speaker, his/her lack of interest in correct expression of the speech, lack of attention and haste. In the book „101 de greșeli gramaticale” I. Nedelcu points out the most commonly encountered causes that trigger language production errors: negligence of morphological and/or syntactical characteristics of words, agreement attraction errors, interference with other languages, hypercorrectness, etc. (Nedelcu 2013, 21-23).
The intralinguistic errors of expression will be regarded together with the errors of CI. To this last category we include lexical and terminological errors, morpho-syntactic errors, ambiguities, incorrect meaning, mistranslation, nonsense; pragmatic errors, additions, omissions, imprecision or vague language, repetitions (reformulations).
It is worth pointing out that the types of errors presented in this paper result exclusively from the interpretation versions provided by the students. A total of 38 errors numbered (1) to (38) were analysed.
Methodology of the study
This experiment was carried out during the first semester of the second year of studies when students are introduced to Consecutive Interpreting. Prior to CI at the Department TIAL students have a wide range of subjects meant to train basic interpreters’ skills such as reaction, attention and concentration control, memory, listening, information analysis and reproduction, utterance building and paraphrasing, public speaking, etc. Students apply these skills during CI classes.
According to the Curriculum, students who have English as a first foreign language have 2 classes of CI per week. Every class lasts for 90 minutes and takes place in a laboratory where students have access to the necessary equipment to perform recorded interpretation. Although in real life performance CI does not require the use of any equipment, due to the fact that the product of interpreting is momentary, in order for the teacher and the students to later have access to the interpretation versions for further assessment of the quality of the product of CI, students are sometimes asked to audio record their TD. At the Department TIAL students record their interpretation versions using the Audacity audio recorder which is a free and open-source digital audio editor and recording application software installed on the laboratory computers.
We have to point out that this empirical study was accomplished after the first five weeks from the start of the CI classes. The reason was to guarantee that students had already acquired the first skills for CI, i.e. attention, concentration and memory.
The subjects for this study were randomly selected from 3 groups of students that have English as their active language. Two groups of 10 students each – Experimental Group (EG) and Control Group (CG) were subject to the experiment. The students in the EG had to consecutively interpret a discourse, having previously accomplished a CI exercise to the discourse. The students who did not do any CI exercise prior to the interpretation of the same discourse constituted the CG. Since I did not have classes of CI at the time of carrying out the experiment, I collaborated with two of my colleagues from the Department in order to conduct the experiment.
Twenty students took part in the case study. Prior to the experiment students were announced about the organization of the experiment. Also they were acknowledged that no reference to their real names will be given in the paper. In order to preserve students’ anonymity we attributed an identification code to substitute for their name. Thus, students in the CG were attributed codes from A1 to A10, and students in the EG were attributed codes from B1 to B10. Also, because we wanted to observe the performance of subjects in the EG before and after applying the pre-interpreting exercise, we used the minus sign to mark the CI without any exercise (EG- and B1-, …, B10-) and the plus sign to indicate the CI with exercise (EG+ and B1+, …, B10+).
Another important aspect to mention is that since no examination tests are required for B.A. admission to Moldova State University we expect a high level of heterogeneity in the groups in terms of linguistic knowledge.
The discourse that students had to interpret is a 1 minute and 44 seconds story in the news at the time the experiment was carried out. It is entitled “U.S. student walkout to protest gun violence” and was selected from the online page Breakingnewsenglish.com. The site is created for didactic purposes and contains lessons (audio files and their transcriptions) from elementary to advanced levels. The audio file was downloaded in mp3 format from the same page. The piece of news we chose pertains to the socio-political domain and is attributed to the pre-intermediate level. One reason behind choosing a pre-intermediate speech is its compliance with the majority of students’ B1 linguistic level according to the Common European Framework of Reference for Languages. Thus, our intention was neither to put students into too much difficulty by choosing a complex discourse nor to give them an easy time by selecting a too easy one. In either case the results could have been compromised.
Both groups under study were provided with a short description about the discourse that reflects its general topic (The speaker speaks about US students protest against gun violence.) and the keywords (high-schoolers, walkout, Stoneman Douglas High School, U.S. Senator Elizabeth Warren, rally, chants, National Rifle Association (NRA).
The pre-interpreting exercise that we applied to the EG before the CI proper of the discourse is a Distributed attention exercise which is cited by A. Gillies in his “Conference Interpreting: A Student’s Practice Book” as Split attention. Distributed or split attention exercise is meant to develop students’ memory and concentration skills by dividing their attention between two different tasks at a time. The tasks the students had to accomplish for his study are detailed in the description of the exercise. The organisation form of the class is individual and pair work and the estimated time to do the exercise is 13 minutes (3 minutes for listening to the discourse and noting down the main ideas + 4 minutes for writing the questions + 6 minutes for answering the questions and correcting the wrong answers if necessary).
Description of exercise (tasks for students):
- While listening to the discourse note down the main ideas. At the same time, try to memorize as much secondary information (details) as possible.
- On the basis of the information that you wrote down and the details that you retained in your memory write 5 special questions to the contents of the discourse without having a second look on the paper with the jotted down information.
- In pairs ask and answer the questions.
- Correct your colleague’s wrong answer(s) to your question(s) if necessary.
Among the teaching-learning techniques used for this exercise we mention:
- Mnemonics to memory (note organization mnemonics) which presupposes graphic and/or mental separation of main ideas of the SD from the details;
- Dialogical interaction reflected through questions and answers;
- Performing with background noise interferences. Since all students are in the same room, they have to do the exercise coping, at the same time, with the noise produced by their colleagues.
Also, since there are no soundproof-booths in the computer laboratory students have to interpret the discourse while there is noise interference produced by the students’ speaking which creates some sort of discomfort for students’ attention and concentration. We explain to the students that it is not uncommon for interpreters to interpret in settings and contexts where there are a lot of disturbing factors. Consequently, there is a great risk of possible attention and concentration loss that students have to deal with. We also tell the students that they have to start recording their interpretation version without further delay, after the speaker stops speaking.
For this experiment students had to interpret the discourse using the short Consecutive interpreting mode without note taking because at this stage of CI competence acquisition students are not introduced to Note-taking techniques yet. Of course, students could have provided a summary translation of the discourse in Romanian if they had listened to the whole discourse but we were interested in obtaining a detailed version of their interpretation rather than in an abridged one. Having this aspect in mind, the speech was divided into 13 logical segments (S) from S1 to S13 as shown in Appendix. I played each segment only once, then I paused the machine after each segment to allow students record their interpretation version. Due to problems caused by faulty equipment two students A3 and A7 did not have their interpretation entirely recorded. Nevertheless, they were included in the data analysis.
For a detailed analysis of the quality of interpretation versions the audio recordings were transcribed. In an attempt of an automated transcription we tried to use speech to text recognition software. Regrettably, the endeavour failed. Despite the fact that students had been repeatedly reminded that they must speak in a loud voice and into the microphone some overlooked the instructions and therefore, some audio files could hardly be heard even at the highest volume. On other occasions, there were some issues with the equipment and the quality of the audio files was questionable. Other times students simply mumbled their speech which was impossible for the machine to perform the speech to text recognition. Also the background noises that can be heard on the recordings added to the inefficiency of automatic transcription of the speeches. Under the circumstances, we were forced to transcribe each audio file by hand. A sample of a transcribed CI is provided in Appendix.
Data analysis and results
In this paragraph we will examine relevant examples of errors selected from the subjects both in the EG and the CG.
The category we intend to start analysing is intralinguistic errors of expression. The most encountered types of such errors among students are redundancy, grammatical disagreement through false attraction, awkward expression, incorrect use of grammatical gender of the noun, pleonasm. Contrary to expectations the lowest rate of this types or errors (14.29%) was registered in the EG- (Figure 1), while after applying the exercise in the same group the rate of errors rose to 32.17% (Figure 1). The rate of intralinguistic errors of expression in the CG was 21.37% (Figure 2). We assume that the reason behind these results lies in EG+ students paying less attention to language correctness and more consideration to lexical accuracy and to rendering the message in its entirety, without omissions.
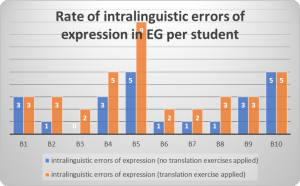
Figure 1. Rate of intralinguistic errors in EG per student

Figure 2. Rate of intralinguistic errors in CG per student
As follows, we will provide some examples of intralinguistic errors of expression caused by inattention, haste or lack of linguistic knowledge. Instances of redundant interpreting were noticed with students A8 and B10-:
(1) A8 „Ei au ales acea dată deoarece ea era data în care se împlinise o lună […].”
(2) B10- „Ei au ales data de 14 martie care marchează data care reprezintă o lună de la data când […].”
Both examples represent cases when extra language components are cumbersome to message transfer. Students could have very well omitted the segments in italics in (1) and (2) and contribute to more correct, smooth communication and economy of the discourse.
We proceed with instances of pleonasms found at students B6+ and B8-.
(3) B6+ „Un student a spus: Această ieșire nu este doar pentru cei care au decedat, dar și pentru cei care urmează să fie următorii.”
(4) B8- „[…] pentru a comemora memoria […].”
The students could have contributed to a more correct language if they reduced the structures in italics to „pentru cei care urmează” and „a comemora” thus, avoiding the superfluousness and awkwardness of expression.
Another itralinguistic error of expression students-interpreters make is the grammatical disagreement through false attraction.
(5) A9 Senatorul Elizabeth Warren s-a prezentat în fața mulțimii și a exprimat că Asociația Națională pentru Armele de Foc sunt foarte periculoase.
In example (5) student A9 falsely attributed the plural verb „sunt” to the singular noun „Asociația Națională pentru Armele de Foc” due to focus on the second half of the noun „Armele de Foc”.
(6) B5 (interpreting exercises applied) „Mulți studenți din grămadă au vrut să-i reamintească președintelui Donald Trump că în 2020 ei vor avea vârsta destulă […] pentru a vota la elecție.”
The examples above (6) fall under the category of awkward expression because they do not collocate. More appropriate versions for „studenți din grămadă” and „vârsta destulă” would be „studenți din mulțime” and „vârsta potrivită”.
The last type of error to mention for this category refers to determining the grammatical gender of the noun.
(7) B6+ „Senatara Elizabeth Warren a vorbit […]”.
The feminine of the word „senator” in Romanian is „senatoare” not „senatară” as stated by student B6+.
As follows we will assess the category of lexical and terminological errors. Among the most encountered types of errors that pertain to this category are linguistic interferences, literal translation and incorrect translation of names of organizations.
(8) Students A1, A2, B7+ and B8+ translated the word „students” as „studenți” when the TD required the word „elevi”. Even if the English noun is known to mean both someone studying at the university and someone who is a school pupil, in the given linguistic context it refers to „school pupils”. This is an example of partial language interference.
(9) Student A1 literally rendered the word combination „gun group” as „grup de arme” when the appropriate interpretation version should have been „grup de interese” or „grup de lobby”.
The last example that pertains to this category of errors was found in student B6- who wrongly translated the name of organization
(10) „National Rifle Association” into „Asociația Națiunilor pentru Arme de Foc”.
It is worth noting that the rate of lexical and terminological errors in the EG+ was lower (13.91%, Figure 5) compared to the rates registered in the CG and in the EG- which were the same: 16.24% to 16.43% (Figures 3 and 4).
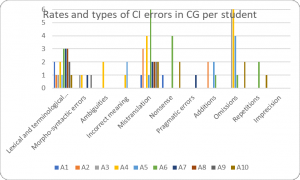
Figure 3. Rates and types of CI errors in CG per student
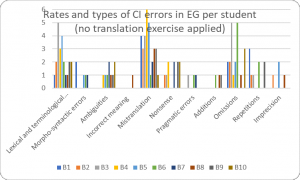
Figure 4. Rates and types of CI errors in EG- per student
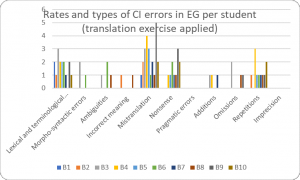
Figure 5. Rates and types of CI errors in EG+ per student
Morpho-syntactical errors amounted to 3.4% in the CG (Figure 3), while in the EG- they represented 5.7% (Figure 4). The lowest rate was registered in the EG+ (2.6%, Figure 5). Such errors in this paper refer to the incorrect verb tense.
(11) A3 „Studenții din Statele Unite iau parte la protestele de miercuri.”
The student-interpreter should have preserved the past simple of the verb in segment S1. „Students in the USA took part in a protest on Wednesday” as required by the linguistic context. Thus, a correct interpretation into Romanian would have been „Studenții din Statele Unite au luat parte la protestele de miercuri.”
Apart from the cacophony produced by the uninspired combination of the two words „deoarece ce”, example (12) contains a similar case of grammatical error. Student B5- had to render the present simple of the verb in S6 „[…] because of what happens in my neighborhood every day” via its present simple Romanian counterpart „din cauza celor ce se întâmplă”. The student failed to do so which caused an alteration of meaning.
(12) B5 „[…] deoarece ce s-a întâmplat în vecinătatea mea […].”
Ambiguities are caused by ignoring the contextual meaning of certain words, adding or omitting some anaphoric references that are necessary for contextual disambiguation.
In S10 „U.S. Senator Elizabeth Warren joined the crowds and spoke at a rally outside the Capitol building” the words in italics (13) were rendered by student B4- in a generalized way which tends to confuse the audience.
(13) „Senatorul Elizavet War s-a alăturat mulțimii și a luat parte la o întâlnire care s-a întâmplat atunci.”
Using more concrete, appropriate to the context equivalents like „demonstraței” or „manifestație” instead of „întâlnire”, which makes an example of lexical ambiguity, as well as avoiding omitting important parts of the discourse could have contributed to interpreting accuracy.
Segment (13) „Many of the students in the crowd wanted to remind President Donald Trump that they would be old enough to vote in the 2020 elections, so he should listen to them now.” was rendered by student A4 as follows:
(14) A4 „Mulți studenți doresc să-i amintească lui Donald Trump că ei vor fi destul de mari pentru a participa la alegeri, de aceea ar trebui să asculte.” The confusion is at grammatical level and lies with the segment in italics. The lack of anaphoric reference represented by personal pronoun „el” which should have substituted the proper noun „Donald Trump”, as well as the personal pronoun „îi” that should have been used in between the conjunction „să” and the verb „asculte” cause ambiguity.
Contrary to the previous example, below (15) we illustrate a case of additional use of reference.
(15) B10 „Mii de studenți au spus că ei vor fi în stare pentru a participa la votarea care va avea loc în 2020. Deci el ar trebui să țină cont de părerea lor acum”. From the context it is not clear who the personal pronoun „el” refers to as student B10- did not make prior reference to any noun that could be substituted by this pronoun.
The same segment S13 was translated into Romanian with some sort of ambiguity by another student.
(16) A5 „Mulți studenți au spus că președintele Donald Trump ar trebui să-i asculte deoarece în anul 2020 ei vor avea vârsta necesară și de aceea el ar trebui să țină cont de cerințele sale.” The use of incorrect possessive pronoun may cause bewilderment for the public audience. The pronoun „sale” refers to third person singular which makes the interpretation quite awkward. In a correct translation version the student should have substituted the noun „studenți” with the possessive pronoun „lor”.
A possible rationale for such errors is that some students could not infer the logical chain in the utterance. As for the rates registered with this category of errors the lowest was among students from the CG (1.71%, Figure 3) while the highest level (6.43%) was in the EG- (Figure 4). A rate of 3.48% was calculated in the EG+.
The next category subject to analysis is incorrect meaning caused by the erroneous meaning in relation to the meaning of the word or sentence in the given context. We will provide two examples in this respect.
(17) A3 „Ei (elevii) au aderat la Asociația Națională pentru Arme de Foc” is contrary to the original meaning” of S9 „They (students) then took part in chants against the powerful gun group the National Rifle Association (NRA)”.
(18) B10- „Acest proces a fost în cinstea celor care nu vor mai fi între noi.” – S5 “The walkout was for those who will never be here again.” The interpretation version introduces the word combination „în cinstea” which refers to people alive and is contrary to the context of the discourse.
The lowest rate of incorrect meaning accounted for 0.7% in the EG- (Figure 4) and the highest (2.5%) in the CG (Figure 3). A rate of 1.7% was registered in the EG+ (Figure 5).
Mistranslation represents the incorrect rendition of the source-message in connection with the original discourse. In this case, the interpretation error resides in attributing a wrong meaning to a word, a phrase, a sentence, etc. contrary to the meaning expressed in the original discourse. The examples below represent alterations of meaning:
(19) S11. „She said: “The NRA has held Congress hostage for years now” was translated by student B9+ as „Ea a declarat că Asociația Națională a Armelor de Foc a ajutat Congresul […]”. We presume that the student misheard the word „held” and interpreted it as „helped” resulting into sense distortion.
(20) B5- „Mii de elevi de liceu nu au fost la școală cu scopul de a participa la protest.” Here we can identify two errors of mistranslation. The first refers to the wrong transfer of the numeral adjective „mii” since the correct translation should have been „zeci de mii”. And the second error „nu au fost la școală” shows change of meaning and can confuse someone who knows the original discourse because an appropriate rendition of this structure in the TL should have been „au ieșit de la oră”. For a comparison we put it side by side with with the original – S2 „Tens of thousands of high-schoolers walked out of their schools to protest against gun violence”.
Here is another error which pertains to the category of numbers:
(21) A1 „Mulți dintre tinerii […] au vrut să-l atenționeze pe […] Donald Trump că în anul 2022 ei vor putea vota […].” The correct year is 2020.
The lowest value of mistranslations (19.66%) was registered in the CG (Figure 3), while the highest (22.86%) was found in the EG+ (Figure 4). A rate of 20.87% of mistranslations was registered in the EG- (Figure 5).
Nonsense is the error that resides in attributing a TL equivalent that totally lacks sense or is absurd. Compared with the incorrect meaning or mistranslation, when the sense transposed into the TD is wrong in relation with the meaning intended by the author of the SD, in the case of nonsense, meaning simply does not exist, which means that the final discourse is incoherent and lacks logic. Instances of nonsense characterized by partial lack of train of thought are indicated as follows:
(22) A6 „Ei au luat parte la grupurile criminale care au aderat la care se numește Asociația Națională pentru Arme”.
(23) B9- „Noi luptăm pentru acei care astăzi nu mai sunt, dar suntem pentru drepturile celor care nu mai sunt astăzi”.
(24) B4- „Mii de studenți au protestat din licee pentru [ăăă] violența care are loc în Statele Unite care sunt cauzate de violență”.
Such cases are attributable to students’ inability to recover the information from the short term memory, difficulties with understanding fragments from the source-message, poor lexical knowledge, and stress.
Figures show that the highest rate of nonsense (9.57%) was identified in the EG+ (Figure 5) while the lowest rate (5.98%) – in the EG- (Figure 3). A rate of 7.14% was attributed to the EG- (Figure 4).
Pragmatic errors are associated with inadequate rendering in the TL of argumentative connectors, discourse markers, forms of address, divergence of discursive cohesion, etc. Analysing students’ interpretation versions we came across instances of inadequate use of register and lack of connectors that ensure the logical and smooth transition of ideas.
(25) B3- „Elizabeth s-a alăturat protestului […].” is an example of disregard of appropriate address of an official, a person of certain status, etc.
(26) A7 „Ei au ales data de 14 februarie se împlinește o lună […]”. The lack of causal conjunction „ întrucât”/ „deoarece” hinders clause connection within the sentence which leads to speech disfluency.
No pragmatic errors were found in the EG+ (Figure 5), while the rates for the EG- and the CG were 2.14% and 0.85% respectively (Figures 3 and 4).
Additions manifest through unjustified insertion of information in the TD. The information added in the TD represents a surplus of information that does not appear in the SD.
(27) Compared to the original S12 „These young people have shown up to free us. I believe the young people will lead us” the extra information in italics provided by student A5 „Eu cred că tinerii ne vor conduce în zilele de azi” produces semantic alteration to the speech.
(28) S6 “I came out because of what happened in Florida […]” contains in the translation of B4+ a suggestive example of information which does not appear in the original and distorts the meaning: „Eu am venit aici deoarece sunt mustrat de ceea ce se întâmplă […]”.
The highest rate of additions (4.27%) was registered in the CG (Figure 3), while the lowest rate (2.14) was in the EG- (Figure 4). A rate of 3% could be noted in the EG+ (Figure 5).
Omissions represent errors that consist in unjustifiably not translating semantic elements from the original discourse. Unjustified omissions of words, phrases or sentences in the examples below are graphically indicated as ”…”.
(30) B3- Un elev a spus: ”…” Un alt student a spus: ”…”.
(31) A5- Acești tineri au ieșit în stradă și au ”…” pentru a ne elibera.
(32) B6- Acești tineri sunt prezenți pentru ”…”.
Causes of omissions among students are most frequently due to their inability to retrieve the source-information, i.e. poor short-term memory, time pressure, and stress. An analysis of the data showed that there is a big discrepancy among students in the EG and CG. Due to the application of interpretation exercise, the lowest rate (3.84%) was in the EG+ (Figure 5) compared to 15% of the same indicator in the EG- (Figure 4). The highest rate (21.3%) was recorded in the CG (Figure 3).
Repeating a word or syntagm twice or thrice may be regarded as the translator’s strategy to gain time for recollecting the message. On the other hand, this technique leads to speech inaccuracy as it is shown in the selected examples:
(33) A10- „Ei au ales această dată deoarece acum o lună acum o lună 17 studenți și-au pierdut viețile”.
(34) B1- „Mulți dintre studenți i-au reamintit președintelui Donald Trump că ei vor fi destul de în vârstă pentru a vota pentru a vota […]”.
(35) B2- „[…] elevii s-au adunat în fața în fața Casei Albe […]”.
(36) B6- „[…] s-au adunat pe terenul de fotbal pentru a pentru a comemora […]”.
The highest rate of repetitions (2.56%) was in the CG (Figure 3), while the lowest rate (6.43%) was in the EG- (Figure 4). A rate of 9.57% was found in the EG+ (Figure 5).
Typical examples of imprecision can be noted in examples (37) and (38) with the same student. A probable cause of making this recurring error lies with the inability to understand the meaning and thus, generalize the information.
(37) B5- „[…] studenții au făcut ceva […]”.
(38) B5- „NRA a făcut ceva […]”.
No such errors were identified in the CG and the EG+. A rate of 2.86% was found in EG- (Figure 4).
Conclusions and suggestions
Summarizing the main findings of this study we may state the following:
- Applying the memory, attention and concentration exercise before the CI of the discourse had a positive effect upon EG+ students whose quality of interpretation was considerably higher in terms of less omissions compared with the CG and EG-.
- Students in the EG+ reported lower error rates in the categories of lexical and terminological errors, morpho-syntactic errors, pragmatic errors, omissions and imprecisions.
- In the EG- compared with the EG+, there was only a slightly low difference in terms of incorrect meaning and additions.
- Students in the CG reported better results in terms of precision. Also, slightly better results in this group were observed with the error categories of mistranslation, nonsense and repetitions.
- Compared with the CG and EG+, the EG- registered lower rates of errors in terms of incorrect meaning and additions.
- The causes of errors are diverse and are generally associated with the linguistic factor, the psychological stress caused by time pressure and lack of general knowledge. The highest rates of errors belonged with the category of mistranslations and lowest rates were with imprecisions.
- Error analysis helps us explore the implications they may have upon the product of interpretation, which is beneficial both for students and the teacher. Making students aware of the impact of errors for the process and product of CI, educating them on how to tackle them will improve the whole teaching and learning process.
Some suggestions to make in the light of this study are connected with the need to conduct replications of the experiment to reinforce the arguments and to have more accurate data. In addition, working with a larger sample size and considering other variables would probably have a bigger statistical value. In a follow-up analysis we intend to analyse the paralinguistic features of the interpretation process and observe the impact upon the product of CI.
References
Breaking news English. U.S. student walkout to protest gun violence. https://breakingnewsenglish.com/1803/180317-student-protests.html. Accessed on 5.03.2018
Gile, Daniel. 2009. Basic Concepts and Models for Interpreter and Translator Training. Amsterdam/Philadelphia: John Benjamins.
Gillies, Andrew. 2013. Conference Interpreting. A student’s practice book. London and New York: Routledge.
Kornakov, Peter. 2000. Five principles and Five Skills for Training Interpreters. IN: Meta. Volume 45 (2): 241-248.
Lungu-Badea, Georgiana. 2012. Mic dicționar de termeni utilizati în teoria, practica și didactica traducerii. Timișoara: Editura Universității de Vest.
Nedelcu, Isabela. 2013. 101 greșeli gramaticale. București: Humanitas.
Nord, Christiane. 2005. Text Analysis: Theory, Methodology and Didactic Application. Amsterdam-New-York: Editions Rodopi.
PACTE. 2005. Investigating translation competence. Conceptual and methodological issues. In: Meta. Volume 50 (2): 609-19.
Phelan, Mary. 2001. The Interpreter’s Resource. Cleveland, Buffalo, Toronto, Sydney: Multilingual Matters LTD.
Sîtnic, Ina. 2017. Abordare didactică a erorilor în interpretarea consecutivă. In: Studia Universitatis Moldaviae. Volume 10 (110): 36-45.